

MSCOCO-EMMA and FigureQA-EMMA
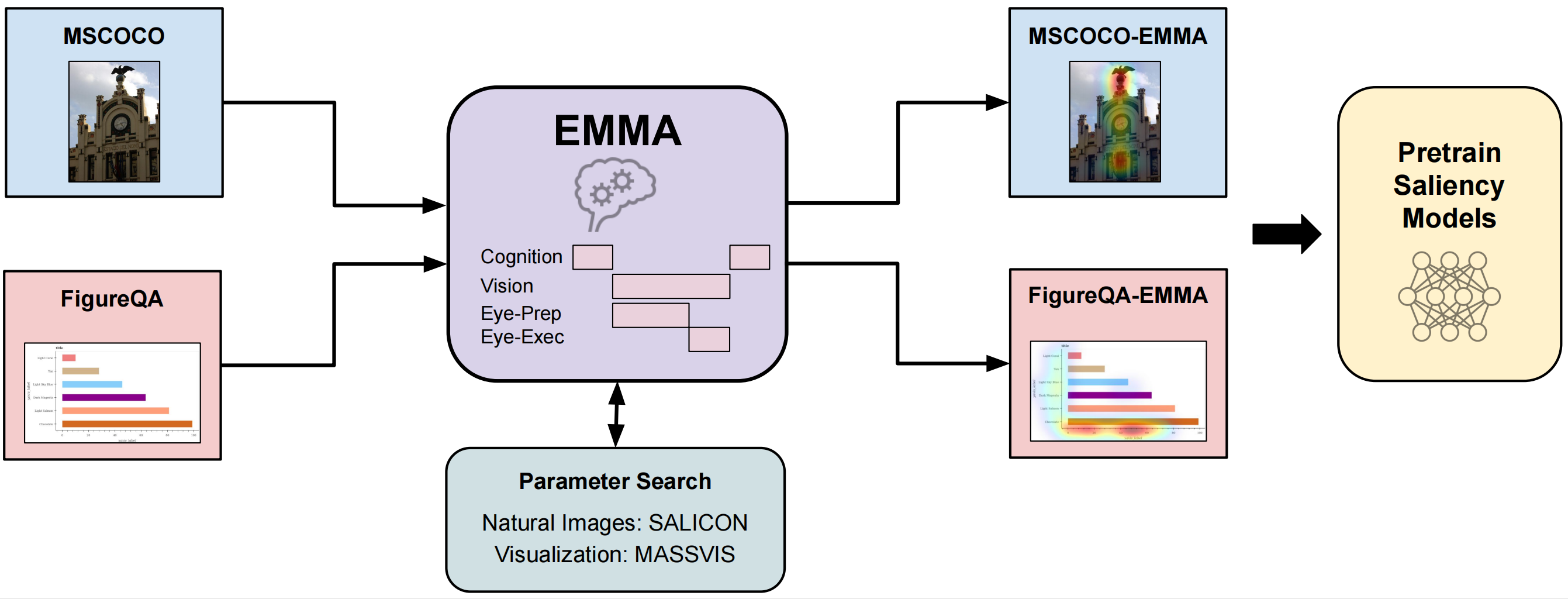
We present a novel method for deep image saliency prediction that leverages a cognitive model of visual attention as an inductive bias. This is in stark contrast to recent purely data-driven models that have achieved performance improvements mainly by increased model capacity, resulting in high computational costs and the need for large scale, domain specific training data. We demonstrate that by leveraging a cognitive model of visual attention, our method achieves competitive performance to the state-of-the-art across several natural image datasets while only requiring a fraction of the parameters.
Furthermore, we set the new state of the art for saliency prediction on information visualizations, demonstrating the effectiveness of our approach for cross-domain generalization.We further provide large-scale cognitively plausible synthetic gaze data on corresponding images in the full MSCOCO and FigureQA datasets, which we used for pre-training. These results are highly promising and underline the significant potential of bridging between first principle cognitive and data-driven models for computer vision tasks, potentially also beyond saliency prediction, and even visual attention.
The full dataset can be requested by contacting us and filling out a license agreement.
Contact: Prof. Andreas Bulling,
The data is only to be used for non-commercial scientific purposes. If you use this dataset in a scientific publication, please cite the following paper:
