

VQA-MHUG
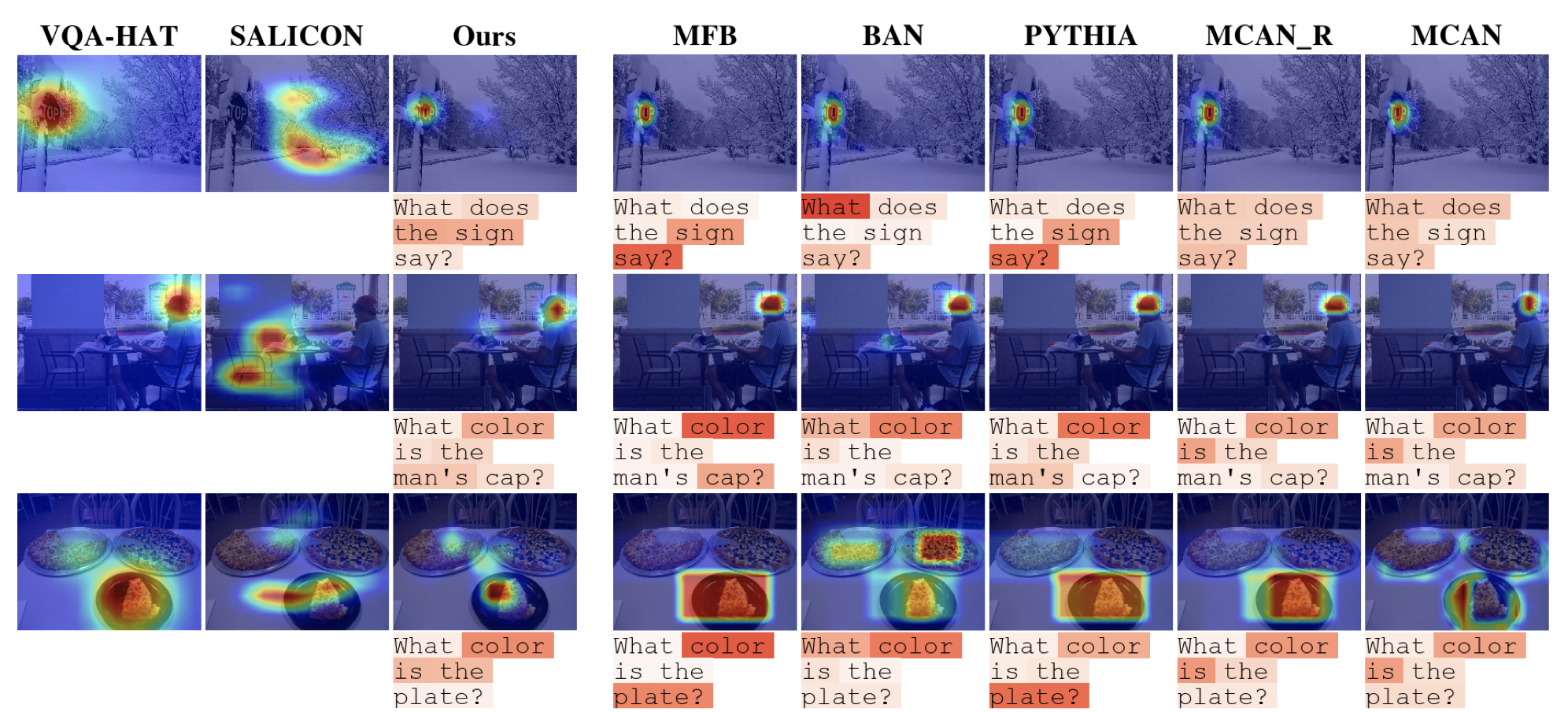
We present VQA-MHUG - a novel 49-participant dataset of multimodal human gaze on both images and questions during visual question answering (VQA), collected using a high-speed eye tracker. To the best of our knowledge, this is the first resource containing multimodal human gaze data over a textual question and the corresponding image. Our corpus encompasses task-specific gaze on a subset of the benchmark dataset VQAv2 val2. Our dataset is unique in that it is the first to provide real human gaze data on both images and corresponding questions and, as such, allows researchers to jointly study human and machine attention.
We use our dataset to analyse the similarity between human and neural attentive strategies learned by five state-of-the-art VQA models: Modulated Co-Attention Network (MCAN) with either grid or region features, Pythia, Bilinear Attention Network (BAN), and the Multimodal Factorised Bilinear Pooling Network (MFB). While prior work has focused on studying the image modality, our analyses show - for the first time - that for all models, higher correlation with human attention on text is a significant predictor of VQA performance. This finding points at a potential for improving VQA performance and, at the same time, calls for further research on neural text attention mechanisms and their integration into architectures for vision and language tasks, including but potentially also beyond VQA.
The full dataset can be requested by filling out an EULA license agreement and send the agreement to pui-office@vis.uni-stuttgart.de.
Contact: Mrs. Daniela Milanese
The data is only to be used for non-commercial scientific purposes. If you use this dataset in a scientific publication, please cite the following paper:
