MPIIGaze: Appearance-Based Gaze Estimation in the Wild
Abstract
Appearance-based gaze estimation is believed to work well in real-world settings, but existing datasets have been collected under controlled laboratory conditions and methods have been not evaluated across multiple datasets. In this work we study appearance-based gaze estimation in the wild. We present the MPIIGaze dataset that contains 213,659 images we collected from 15 participants during natural everyday laptop use over more than three months. Our dataset is significantly more variable than existing ones with respect to appearance and illumination. We also present a method for in-the-wild appearance-based gaze estimation using multimodal convolutional neural networks that significantly outperforms state-of-the art methods in the most challenging cross-dataset evaluation. We present an extensive evaluation of several state-of-the-art image-based gaze estimation algorithms on three current datasets, including our own. This evaluation provides clear insights and allows us to identify key research challenges of gaze estimation in the wild.
Download (2.1 Gb).
The data is only to be used for non-commercial scientific purposes. If you use this dataset in a scientific publication, please cite the following paper:
-

MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 41 (1), pp. 162-175, 2019.
-

Appearance-based Gaze Estimation in the Wild
Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4511-4520, 2015.
Collection Procedure
We implemented custom software running as a background service on participants’ laptops. Every 10 minutes the software automatically asked participants to look at a random sequence of 20 on-screen positions (a recording session), visualized as a grey circle shrinking in size and with a white dot in the middle. Participants were asked to fixate on these dots and confirm each by pressing the spacebar once the circle was about to disappear. This was to ensure participants concentrated on the task and fixated exactly at the intended on-screen positions. No other instructions were given to them, in particular no constraints as to how and where to use their laptops.
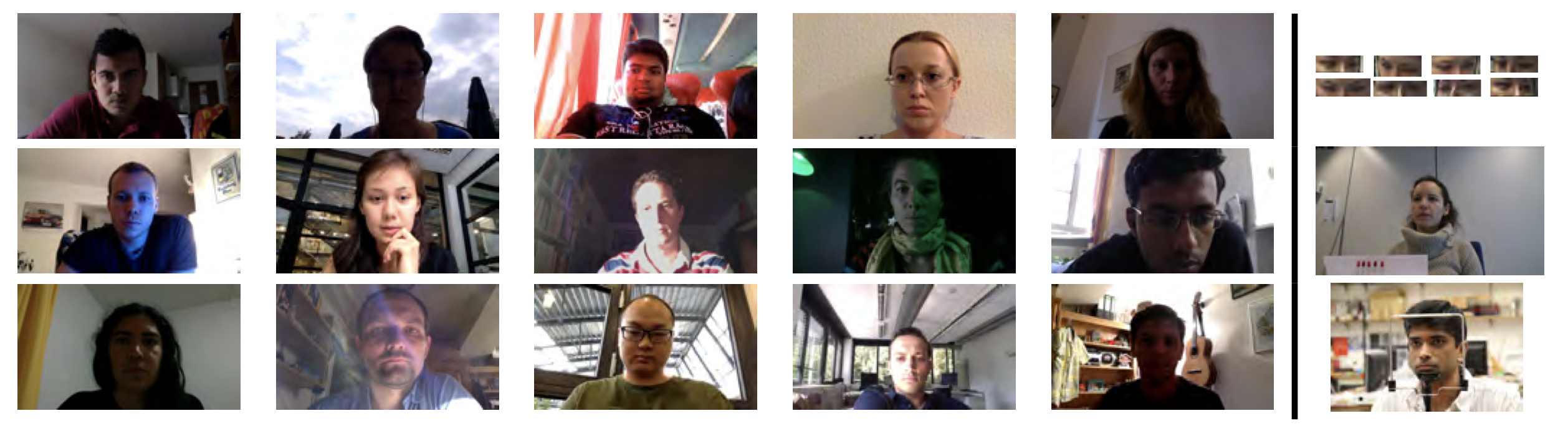
Characteristics
We collected a total of 213,659 images from 15 participants. The number of images collected by each participant varied from 34,745 to 1,498.
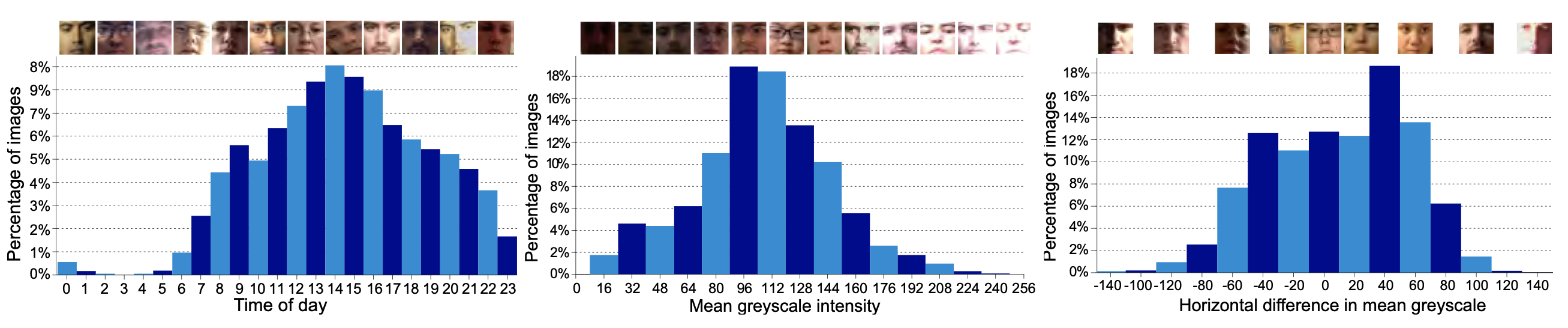
The following figure shows the the collected samples across different factors, including: percentage of images having different mean grey-scale intensities within the face region (top left), having horizontally different mean grey-scale intensities from the left to right half of the face region (to right), collected at different times over the day (bottom left), and collected by each participants. Some figures with representative samples at the top.
Dataset
We present the MPIIGaze dataset that contains 213,659 images that we collected from 15 participants during natural everyday laptop use over more than three months. The number of images collected by each participant varied from 34,745 to 1,498. Our dataset is significantly more variable than existing ones with respect to appearance and illumination.
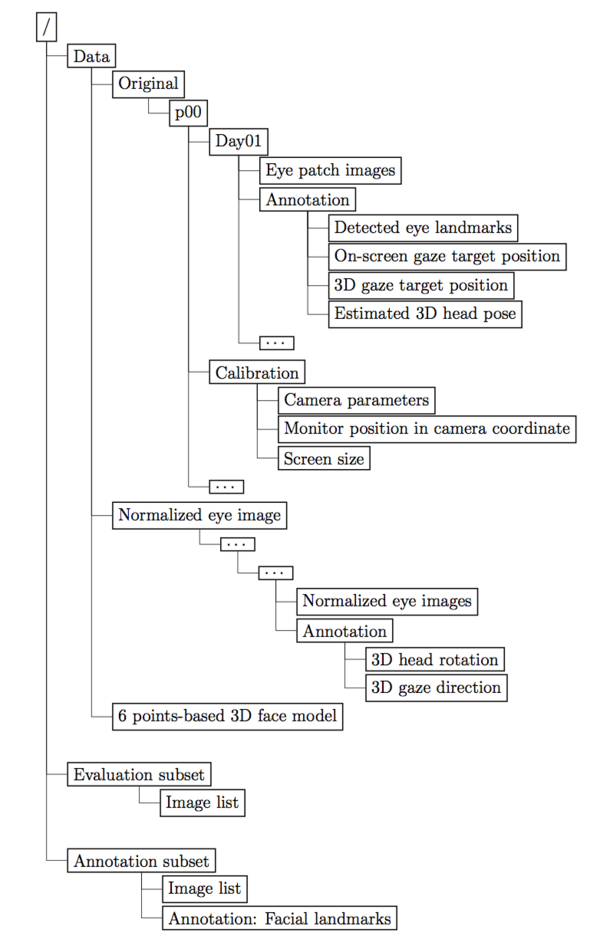
The dataset contains three parts: “Data”, “Evaluation Subset” and “Annotation subset”.
* The “Data” includes “Original”, “Normalized” and “Calibration” for all the 15 participants.
* The “Evaluation Subset” contains the image list that indicates the selected samples for the evaluation subset in our paper.
* The “Annotation Subset” contains the image list that indicates 10,848 samples that we manually annotated, following the annotations with (x, y) position of 6 facial landmarks (four eye corners, two mouth corners) and (x,y) position of two pupil centers for each of above images.
The dataset contains three parts: "Data'', "Evaluation Subset'' and "Annotation subset''. The "Data'' folder includes "Original'' and "Normalized'' for all the 15 participants. You can also find the 6 points-based face model we used in this dataset.
The "Original'' folders are the cropped eye rectangle images with the detection results based on face detector [1] and facial landmark detector [2]. For each participants, the images and annotations are organized by days. For each day's folder, there are the image collected by that participants and corresponding "annotation.txt" files. The annotations includes:
* Dimension 1~24: Detected eye landmarks position in pixel on the whole image coordinate
* Dimension 25~26: On-screen gaze target position in screen coordinate
* Dimension 27~29: 3D gaze target position related to camera
* Dimension 30~35: The estimated 3D head pose based on 6 points-based 3D face model, rotation and translation: we implement the same 6 points-based 3D face model in [3], which includes the four eye corners and two mouth corners
* Dimension 36~38: The estimated 3D right eye center in the camera coordiante system.
* Dimension 39~41: The estimated 3D left eye center in the camera cooridnate system.
Besides, there is also "Calibration" folder for each participants, which contains:
* Camera.mat: the intrinsic parameter of the laptop camera. "cameraMatrix": the projection matrix of the camera. "distCoeffs": camera distortion coefficients. "retval": root mean square (RMS) re-projection error. "rvecs": the rotation vectors. "tvecs": the translation vectors.
* monitorPose.mat: the position of image plane in camera coordinate. "rvecs": the rotation vectors. "tvecs": the translation vectors.
* screenSize.mat: the laptop screen size. "height_pixel": the screen height in pixel. "width_pixel": the screen width in pixel. "height_mm": the screen height in millimeter. "width_mm": the screen widht in millimeter.
The "Normalized'' folders are the eye patch images after the normalization that canceling scaling and rotation via perspective transformation in Sugano et al. [3]. Similar to the "Original'' folders, all the data are organized by each days for each participants, and the file format is ".mat". The annotation includes: * 3D gaze head pose and 3D gaze direction. The generation of 2D screen gaze target to this 3D gaze direction is described in our paper.
The folder "Evaluation Subset'' contains:
* The image list that indicates the selected samples for the evaluation subset in our paper. We performed evaluations on this evaluation subset of our MPIIGaze dataset, which includes equal number of samples for each participants.
The folder "Annotation Subset'' contains:
* The image list that indicates 10,848 samples that we manually annotated
* Following the annotations with (x, y) position of 6 facial landmarks (four eye corners, two mouth corners) and (x,y) position of two pupil centers for each of above images.
The comparison of the original eye rectangle and normalized eye patch is shown in the following figure.

File Structure
See image on the right for the file structure.
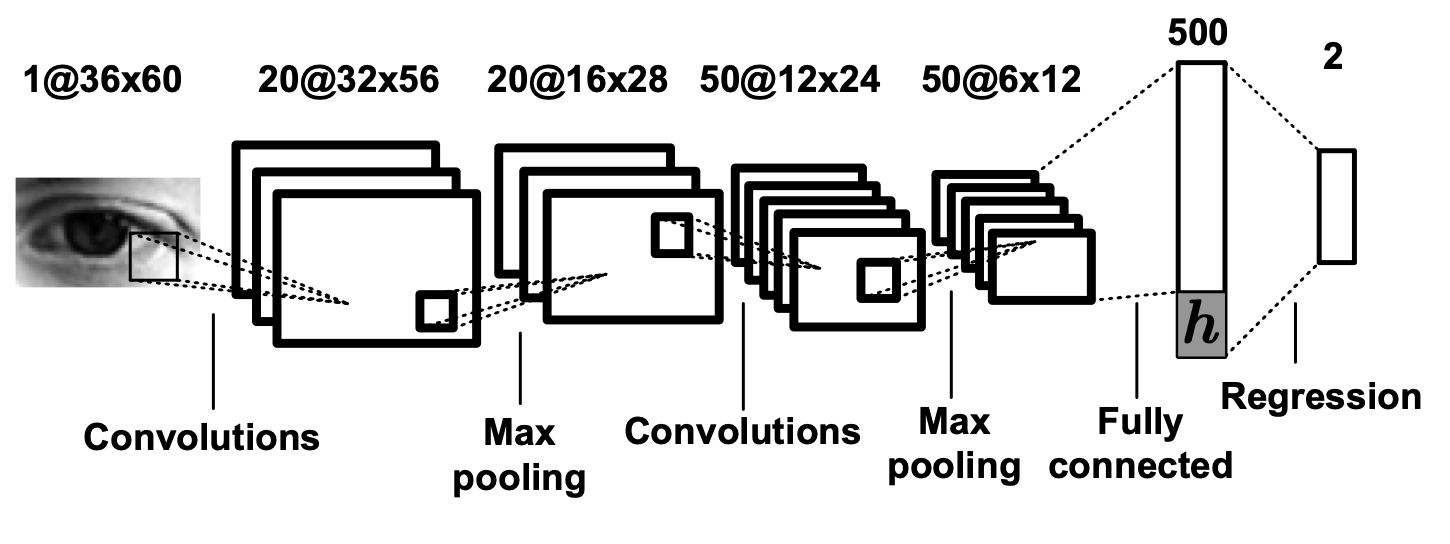
Method: Multimodal Convolutional neural networks (CNN)
We first employ state-of-the-art face detection and facial landmark detection methods to locate landmarks in the input image obtained from the calibrated monocular RGB camera. We then fit a generic 3D facial shape model to estimate 3D poses of the detected faces and apply the space normalization technique proposed in [3] to crop and warp the head pose and eye images to the normalized training space. The CNN is used to learn the mapping from the head poses and eye images to gaze directions in the camera coordinate system.
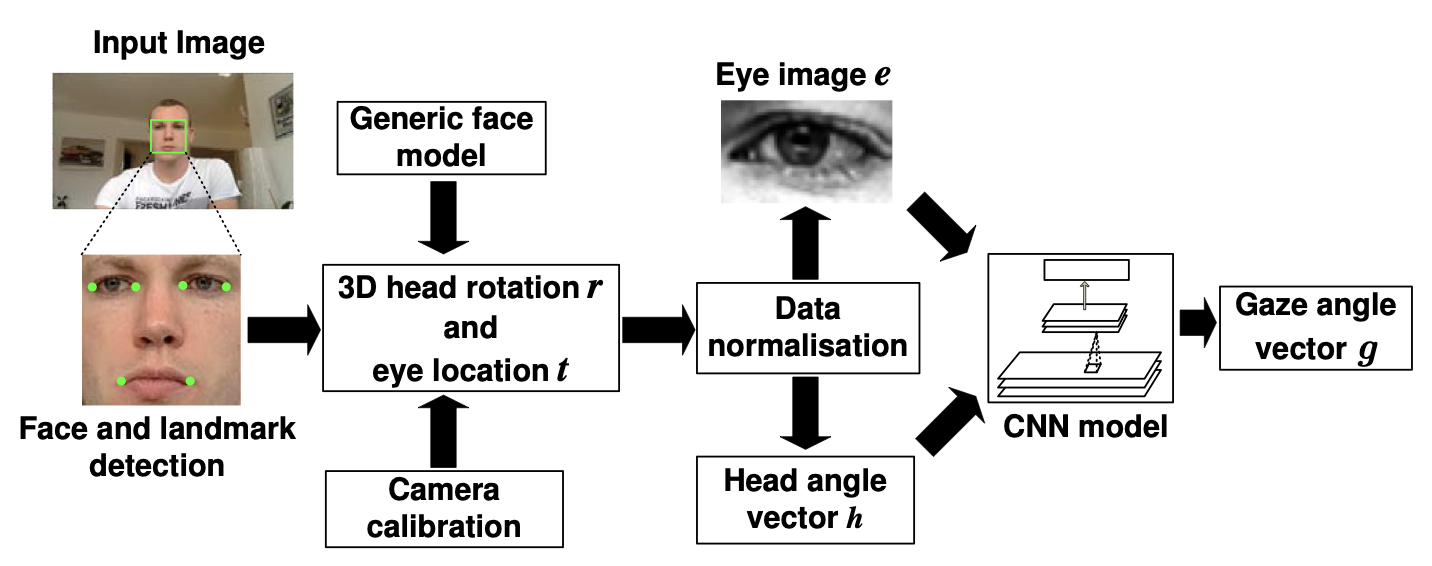
We propose a multimodal CNN-based model for the appearance-based gaze estimation method. The Basic structure of this CNN model includes two convolutional layers and one fully connected layer, and a linear regression on the top. We put head pose information into this CNN model by concatenating head pose angle vector with the output of the fully connected layer. The architectural of our CNN-based model is showed in the following figure.
We train this model based on Caffe. You can download the configuration file here. As the main parameter, leaning rate is set to be 0.1.
Please notice that you also need modify the "accuracy" and "euclidean distance" layers of Caffe. You can download it here.
Q&A
How do you convert .mat file to .h5 file?
Please find the example Matlab script here.
How do you convert 3d directional vector to 2d angle?
We refer to the paper [3] for the data normalization. Briefly to say, the 3D gaze direction (x, y, z) can be converted to 2D representation (theta, phi) like:
theta = asin(-y)phi = atan2(-x, -z)
The negative representation has been used so that camera-looking direction becomes (0,0).
And in contrast, 3D head rotation (x, y, z) can be converted to (theta, phi) like:
M = Rodrigues((x,y,z))
Zv = (the third column of M)
theta = asin(Zv[1])
phi = atan2(Zv[0], Zv[2])
Why did I get "nan" during training?
Usually, there are two reasons to cause "nan". Firstly, it can be the value is out of the float type range if you got "nan" all the time. It can happen with inappropriate layer initialization. Since Caffe is keeping update, my configuration also can fail the layer initialization. So please modify the layer initialization parameter by yourself, like the "std" value. Secondly, it can be caused by calculation exception if you got "nan" from time to time. I modify the accuracy layer and euclidean loss layer to report the "angle difference", where the function "acos" is been called. It sometimes output "nan" because the variable is out the range of (-1,1). However, it is just for showing, so that wouldn't affect the training.
How can I do data normalization?
Please refer to this example code for how to convert the data from "Original" to "Normalized".
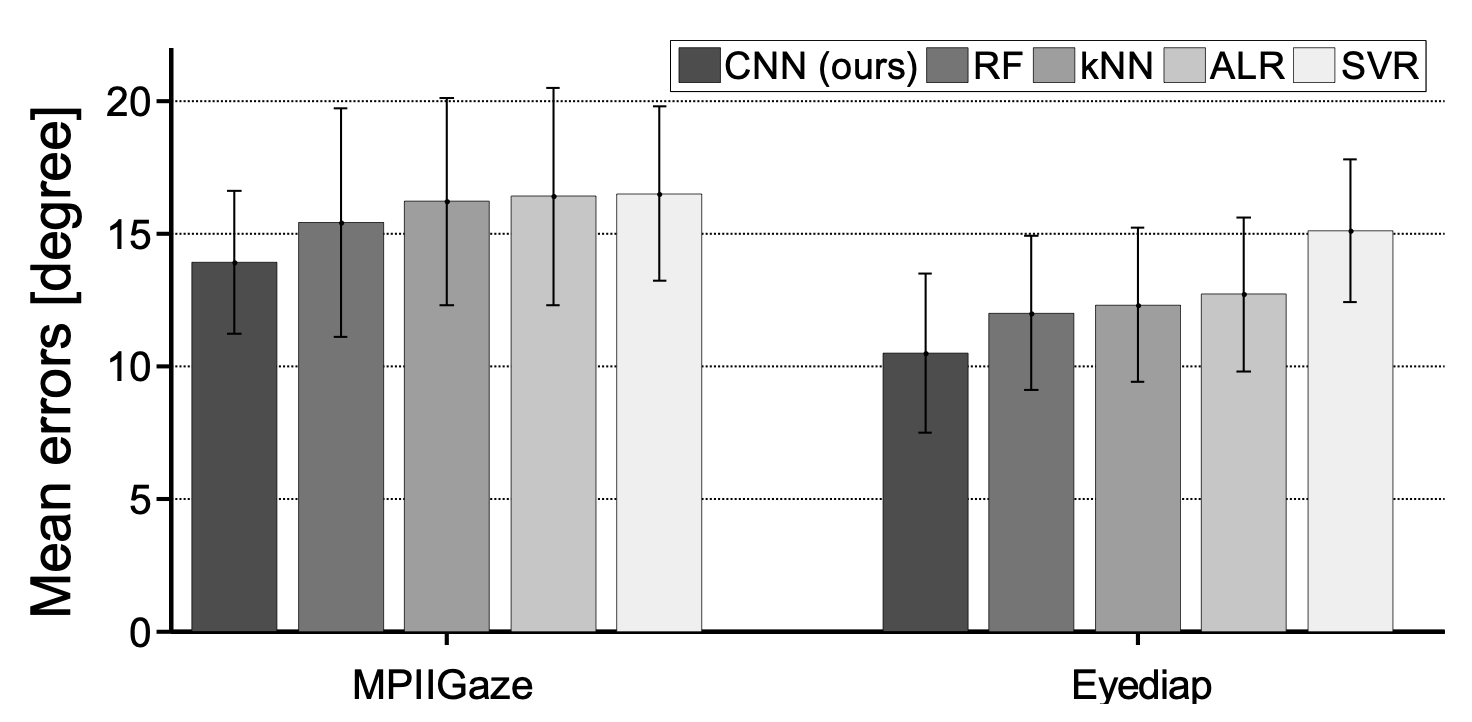
Evaluation: Cross-dataset Evaluation
We selected the UT Multiview [3] dataset as the training dataset because it covers the largest area in head and gaze angle space (see following figure). In addition to our MPIIGaze dataset, we also show results using the Eyediap dataset [4] as test data.
In this setting, our CNN-based approach shows the best accuracy on both datasets (13.9 degrees on MPIIGaze, 10.5 degrees on Eyediap), with a significant performance gain (10% on MPIIGaze, 12% on Eyediap, paired Wilcoxon test, p < 0.05) over the state-of-the-art RF method. However, performance on MPIIGaze is generally worse than on the Eyediap dataset, which indicates the fundamental difficulty of the in-the-wild setting.
 </p>
</p>
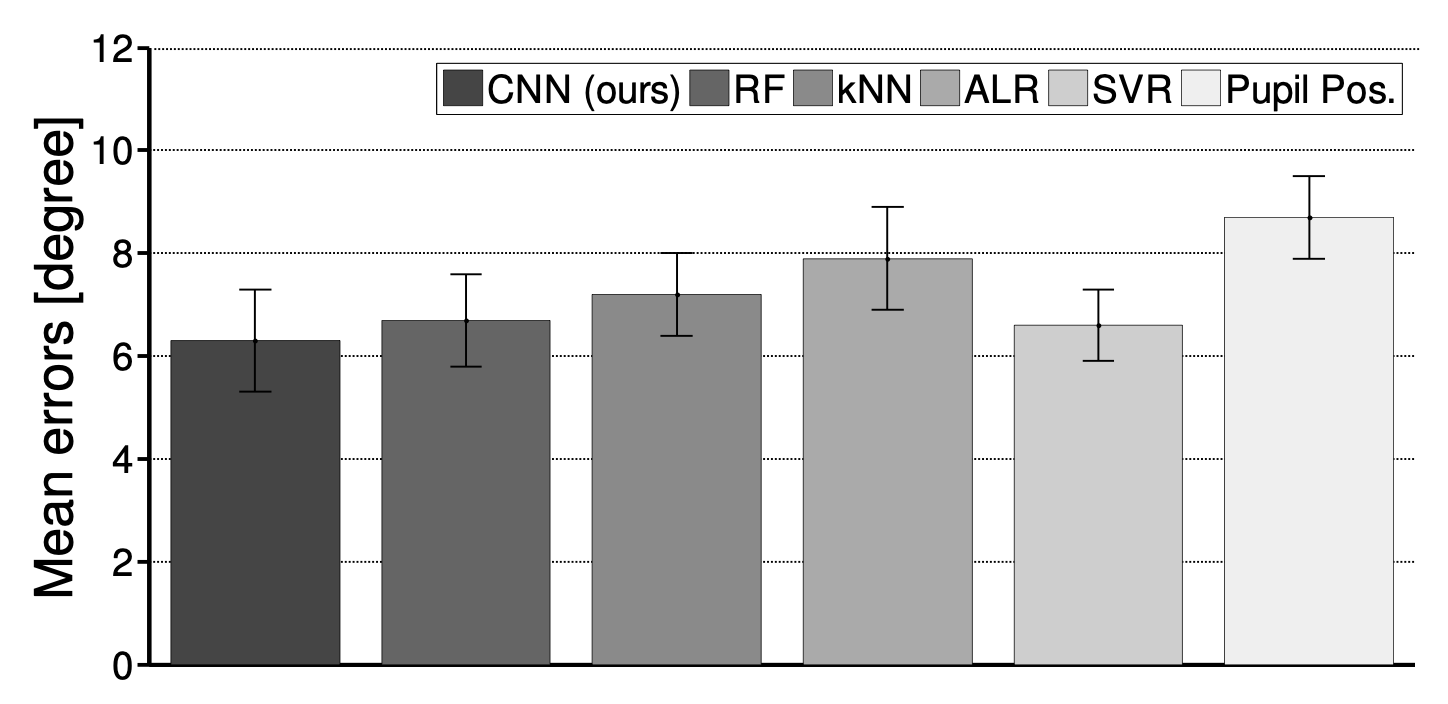
Evaluation: Within-dataset Evaluation
To discuss the limits of person-independent performance on the MPIIGaze dataset, we performed leave-one-person-out evaluation on the MPIIGaze dataset.
All appearance-based methods showed better performances than in previous cross-dataset evaluation, and this indicates the importance of dataset- or domain-specific training data for appearance-based gaze estimation methods. Although its performance gain over the other baseline methods becomes smaller in this setting, our CNN-based method still performed the best among them with 6.3 degrees mean error.
References
[1] T. Baltrušaitis, P. Robinson, and L.-P. Morency. Continuous conditional neural fields for structured regression. In Computer Vision–ECCV 2014, pages 593–608. Springer, 2014.
[2] J. Li and Y. Zhang. Learning surf cascade for fast and accurate object detection. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 3468–3475. IEEE, 2013.
[3] Y. Sugano, Y. Matsushita, and Y. Sato. Learning-by-synthesis for appearance-based 3d gaze estimation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 1821–1828. IEEE, 2014.
[4] M. K. A. Funes, F. Monay, and J.-M. Odobez. EYEDIAP: a database for the development and evaluation of gaze estimation algorithms from RGB and RGB-D cameras. Proceedings of the Symposium on Eye Tracking Research and Applications (ETRA), pages 255-258. ACM, 2014.