Multimodal Integration of Human-Like Attention in Visual Question Answering
Ekta Sood, Fabian Kögel, Philipp Müller, Dominike Thomas, Mihai Bâce, Andreas Bulling
arxiv:2109.13139, pp. 1–11, 2021.
Abstract
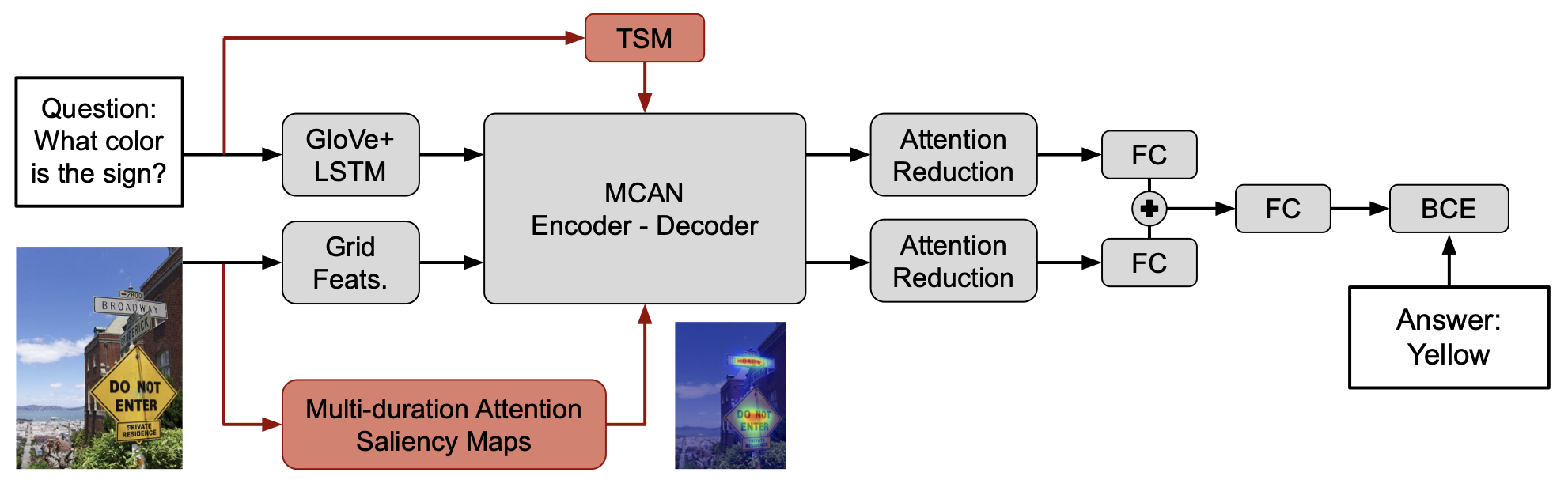
Human-like attention as a supervisory signal to guide neural attention has shown significant promise but is currently limited to uni-modal integration – even for inherently multi-modal tasks such as visual question answering (VQA). We present the Multimodal Human-like Attention Network (MULAN) – the first method for multimodal integration of human-like attention on image and text during training of VQA models. MULAN integrates attention predictions from two state-of-the-art text and image saliency models into neural self-attention layers of a recent transformer-based VQA model. Through evaluations on the challenging VQAv2 dataset, we show that MULAN achieves a new state-of-the-art performance of 73.98% accuracy on test-std and 73.72% on test-dev and, at the same time, has approximately 80% fewer trainable parameters than prior work. Overall, our work underlines the potential of integrating multimodal human-like and neural attention for VQA.Links
Paper: sood21_arxiv.pdf
Paper Access: https://arxiv.org/pdf/2109.13139.pdf
BibTeX
@techreport{sood21_arxiv,
author = {Sood, Ekta and Kögel, Fabian and Müller, Philipp and Thomas, Dominike and Bâce, Mihai and Bulling, Andreas},
title = {Multimodal Integration of Human-Like Attention in Visual Question Answering},
year = {2021},
url = {https://arxiv.org/pdf/2109.13139.pdf},
pages = {1--11}
}