Interpreting Attention Models with Human Visual Attention in Machine Reading Comprehension
Ekta Sood, Simon Tannert, Diego Frassinelli, Andreas Bulling, Ngoc Thang Vu
arxiv:2010.06396, pp. 1–14, 2020.
Abstract
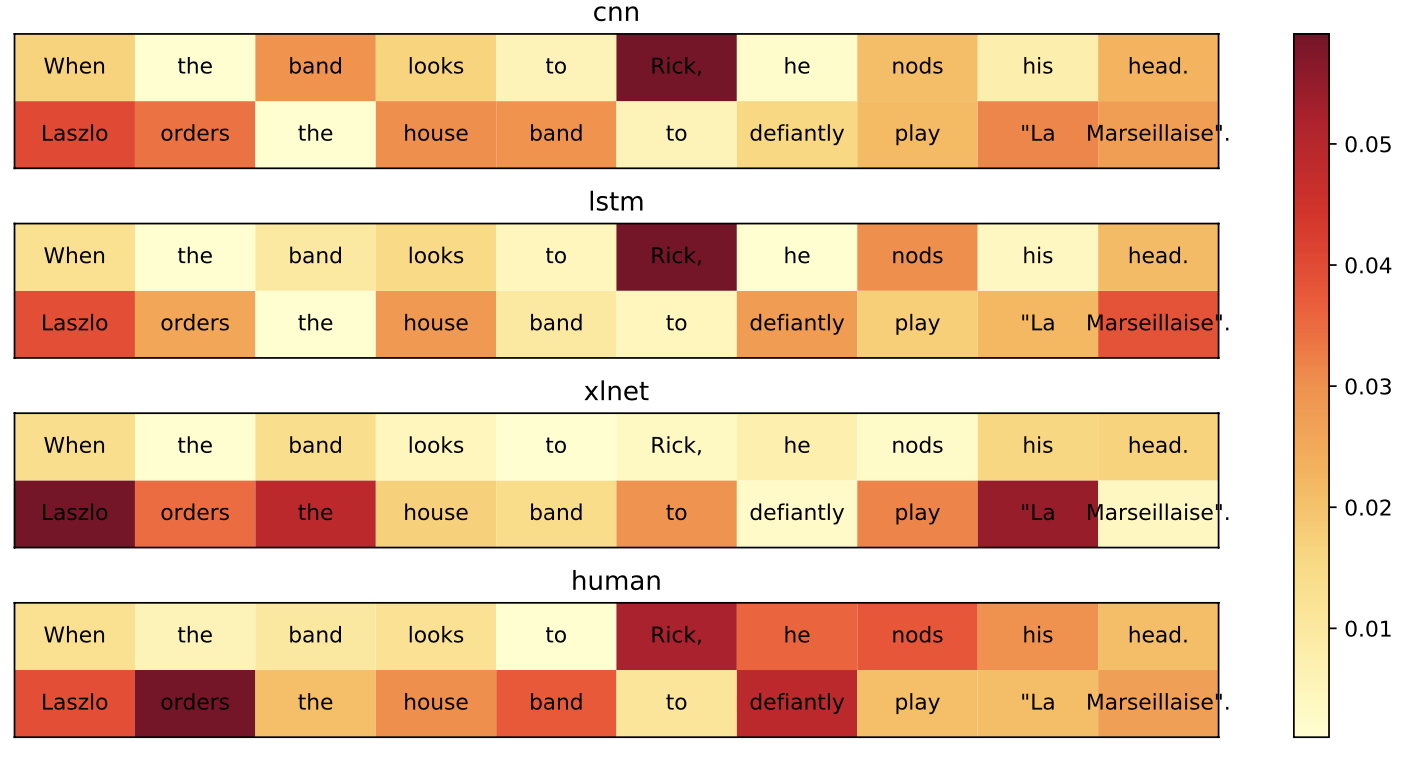
While neural networks with attention mecha- nisms have achieved superior performance on many natural language processing tasks, it remains unclear to which extent learned attention resembles human visual attention. In this paper, we propose a new method that leverages eye-tracking data to investigate the relationship between human visual attention and neural attention in machine reading comprehension. To this end, we introduce a novel 23 participant eye tracking dataset - MQA-RC, in which participants read movie plots and answered pre-defined questions. We compare state of the art networks based on long short-term memory (LSTM), convolutional neural models (CNN) and XLNet Transformer architectures. We find that higher similarity to human attention and performance significantly correlates to the LSTM and CNN models. However, we show this relationship does not hold true for the XLNet models – despite the fact that the XLNet performs best on this challenging task. Our results suggest that different architectures seem to learn rather different neural attention strategies and similarity of neural to human attention does not guarantee best performance.Links
Paper: sood20_arxiv_2.pdf
Code: https://git.hcics.simtech.uni-stuttgart.de/public-projects/visualizing-human-and-neural-attention
Paper Access: https://arxiv.org/abs/2010.06396
Dataset: https://collaborative-ai.org/research/datasets/MQA-RC/
BibTeX
@techreport{sood20_arxiv_2,
title = {Interpreting Attention Models with Human Visual Attention in Machine Reading Comprehension},
author = {Sood, Ekta and Tannert, Simon and Frassinelli, Diego and Bulling, Andreas and Vu, Ngoc Thang},
year = {2020},
url = {https://arxiv.org/abs/2010.06396},
pages = {1--14}
}