Video Language Co-Attention with Multimodal Fast-Learning Feature Fusion for VideoQA
Adnen Abdessaied*, Ekta Sood*, Andreas Bulling
Proc. of the 7th Workshop on Representation Learning for NLP (Repl4NLP), pp. 1–12, 2022.
Abstract
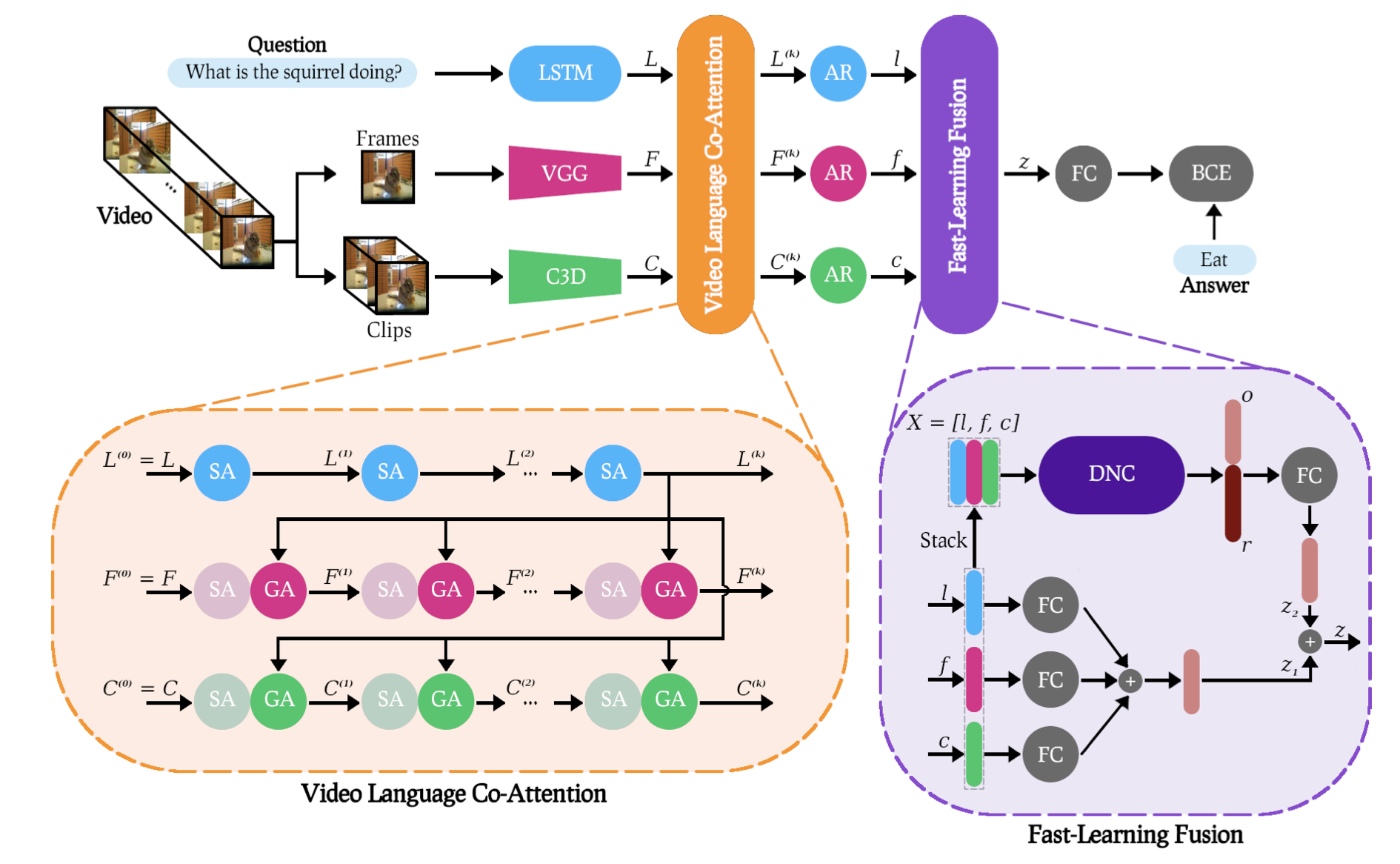
[Equal contribution by the first two authors.] We propose the Video Language Co-Attention Network (VLCN) – a novel memory-enhanced model for Video Question Answering (VideoQA). Our model combines two original contributions: A multimodal fast-learning feature fusion (FLF) block and a mechanism that uses self-attended language features to separately guide neural attention on both static and dynamic visual features extracted from individual video frames and short video clips. When trained from scratch, VLCN achieves competitive results with the state of the art on both MSVD-QA and MSRVTT-QA with 38.06% and 36.01% test accuracies, respectively. Through an ablation study, we further show that FLF improves generalization across different VideoQA datasets and performance for question types that are notoriously challenging in current datasets, such as long questions that require deeper reasoning as well as questions with rare answers.Links
Paper: abdessaied22_repl4NLP.pdf
Code: https://git.hcics.simtech.uni-stuttgart.de/public-projects/vlcn
BibTeX
@inproceedings{abdessaied22_repl4NLP,
author = {Abdessaied*, Adnen and Sood*, Ekta and Bulling, Andreas},
title = {Video Language Co-Attention with Multimodal Fast-Learning Feature Fusion for VideoQA},
booktitle = {Proc. of the 7th Workshop on Representation Learning for NLP (Repl4NLP)},
year = {2022},
pages = {1--12}
}